Die digitale Welt verändert sich rasant. Während wir uns jahrelang auf klassisches Suchmaschinenmarketing- und -Optimierung (SEM & SEO) konzentriert haben, rückt nun ein neues Paradigma in den Fokus: Agentic Web.
Für Unternehmen bedeutet dies, dass es nicht mehr nur darum geht, von Menschen über Suchmaschinen gefunden zu werden, sondern auch von autonomen KI-Agenten und automatisierten Systemen.
Führende Technologie-Entscheider wie Google, Microsoft, GoDaddy, Hugging Face, Nvidia, Salesforce, ServiceNow, Databricks, Snowflake, GitHub und Cisco haben hierfür einen neuen, offenen Standard ins Leben gerufen: die Agentic Resource Discovery (ARD) Spezifikation.
Ob und in welchem Umfang sich dieser Standard flächendeckend durchsetzt, wird sich zeigen. Eines ist jedoch sicher: Wer dieses Protokoll ignoriert, riskiert, in den kuratierten Antworten und Transaktionen von KI-Systemen unsichtbar zu werden. Das Risiko steht in keinem Verhältnis zum relativ geringen Implementierungsaufwand.
Was ist Agentic Resource Discovery (ARD)?
Bisher basierte das Internet der KI-Systeme primär auf manuellen Integrationen. Wenn Sie einen KI-Agenten oder ein LLM nutzen wollten , mussten Sie im Vorfeld definieren, welche APIs oder Tools (z. B. über das Model Context Protocol – MCP) angesprochen werden dürfen. Das ist statisch und skaliert nicht.
Agentic Resource Discovery (ARD) löst dieses Problem fundamental. ARD ist ein offenes, dezentrales Protokoll – vergleichbar mit dem DNS-System des klassischen Internets – , das es KI-Agenten ermöglicht, relevante Ressourcen, APIs und spezialisierte Fähigkeiten zur Laufzeit autonom zu suchen, zu finden und zu verifizieren.
Anstatt dass Entwickler jede API manuell im Code verdrahten müssen, sucht der KI-Agent auf Basis der Absicht (Intent) des Nutzers in einem föderierten Verzeichnis nach der besten Fähigkeit, verifiziert die Quelle und führt die Aktion direkt aus.
Der Unterschied in der Praxis:
- Klassischer Ansatz (Pre-ARD): Ein KI-Assistent kann nur die Tools nutzen, die der Entwickler hart im Code hinterlegt hat.
- Agentic-Ready-Ansatz (ARD): Ein Kunde bittet seinen KI-Agenten: „Finde mir die wirtschaftlichste Cyber-Versicherung für unseren Fuhrpark, vergleiche die Deckungssummen und bereite den digitalen Abschluss vor.“ oder „Finde mir einen lokalen Dienstleister, der heute noch meine Heizung reparieren kann, und buche einen Termin.“ Der Agent durchsucht das ARD-Verzeichnis, findet die offengelegte Buchungs-API Ihres Unternehmens, verifiziert Ihre Domain und schließt den Prozess ab.
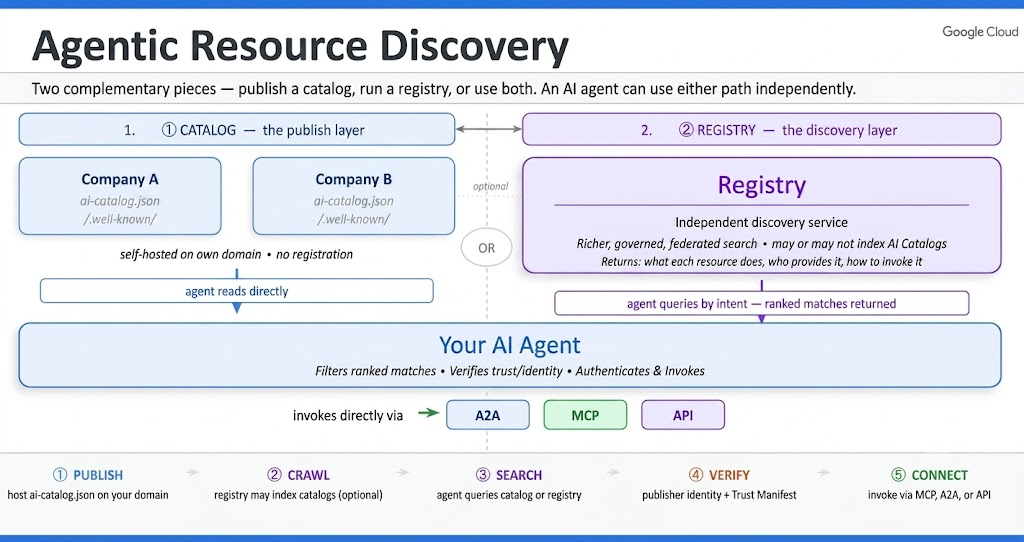
Technische Funktionsweise: Catalogs & Registries
Die ARD-Architektur beruht auf zwei tragenden Säulen, die das Vertrauens- und Suchmodell des agentischen Webs definieren:
- Catalogs (Kataloge): Jedes Unternehmen veröffentlicht eine maschinenlesbare Manifestdatei namens ai-catalog.json direkt auf der eigenen Domain unter einem standardisierten, geschützten Pfad. Da diese Datei auf Ihrem eigenen Webserver liegt, dient die Inhaberschaft der Domain als kryptografisches Fundament für Vertrauen und Identität.
- Registries (Register): Registries funktionieren wie Suchmaschinen für KI-Agenten. Sie crawlen das Web nach veröffentlichten ai-catalog.json-Dateien, indexieren deren Inhalte semantisch und machen sie über eine standardisierte API (z. B. POST /search) für anfragende KI-Clients durchsuchbar.
Quelle: https://developers.googleblog.com/announcing-the-agentic-resource-discovery-specification/
Die Struktur der ai-catalog.json: Das technische Datenmodell
Damit Registries und Agenten deine Schnittstellen fehlerfrei interpretieren können, muss die ai-catalog.json exakt nach der ARD-Spezifikation aufgebaut sein.
Ein kritischer Stolperstein in der Praxis ist die „Strict Value-or-Reference“-Bedingung des Katalogs: Ein Eintrag darf für seine technische Definition entweder nur das Feld url (Verweis auf eine externe Schnittstellendefinition) oder das Feld data (Direkteinbettung des Schemas) nutzen – niemals beide gleichzeitig.


