Die digitale Welt verändert sich rasant. Während wir uns jahrelang auf klassisches Suchmaschinenmarketing- und -Optimierung (SEM & SEO) konzentriert haben, rückt nun ein neues Paradigma in den Fokus: Agentic Web.
Für Unternehmen bedeutet dies, dass es nicht mehr nur darum geht, von Menschen über Suchmaschinen gefunden zu werden, sondern auch von autonomen KI-Agenten und automatisierten Systemen.
Führende Technologie-Entscheider wie Google, Microsoft, GoDaddy, Hugging Face, Nvidia, Salesforce, ServiceNow, Databricks, Snowflake, GitHub und Cisco haben hierfür einen neuen, offenen Standard ins Leben gerufen: die Agentic Resource Discovery (ARD) Spezifikation.
Ob und in welchem Umfang sich dieser Standard flächendeckend durchsetzt, wird sich zeigen. Eines ist jedoch sicher: Wer dieses Protokoll ignoriert, riskiert, in den kuratierten Antworten und Transaktionen von KI-Systemen unsichtbar zu werden. Das Risiko steht in keinem Verhältnis zum relativ geringen Implementierungsaufwand.
Was ist Agentic Resource Discovery (ARD)?
Bisher basierte das Internet der KI-Systeme primär auf manuellen Integrationen. Wenn Sie einen KI-Agenten oder ein LLM nutzen wollten , mussten Sie im Vorfeld definieren, welche APIs oder Tools (z. B. über das Model Context Protocol – MCP) angesprochen werden dürfen. Das ist statisch und skaliert nicht.
Agentic Resource Discovery (ARD) löst dieses Problem fundamental. ARD ist ein offenes, dezentrales Protokoll – vergleichbar mit dem DNS-System des klassischen Internets – , das es KI-Agenten ermöglicht, relevante Ressourcen, APIs und spezialisierte Fähigkeiten zur Laufzeit autonom zu suchen, zu finden und zu verifizieren.
Anstatt dass Entwickler jede API manuell im Code verdrahten müssen, sucht der KI-Agent auf Basis der Absicht (Intent) des Nutzers in einem föderierten Verzeichnis nach der besten Fähigkeit, verifiziert die Quelle und führt die Aktion direkt aus.
Der Unterschied in der Praxis:
- Klassischer Ansatz (Pre-ARD): Ein KI-Assistent kann nur die Tools nutzen, die der Entwickler hart im Code hinterlegt hat.
- Agentic-Ready-Ansatz (ARD): Ein Kunde bittet seinen KI-Agenten: „Finde mir die wirtschaftlichste Cyber-Versicherung für unseren Fuhrpark, vergleiche die Deckungssummen und bereite den digitalen Abschluss vor.“ oder „Finde mir einen lokalen Dienstleister, der heute noch meine Heizung reparieren kann, und buche einen Termin.“ Der Agent durchsucht das ARD-Verzeichnis, findet die offengelegte Buchungs-API Ihres Unternehmens, verifiziert Ihre Domain und schließt den Prozess ab.
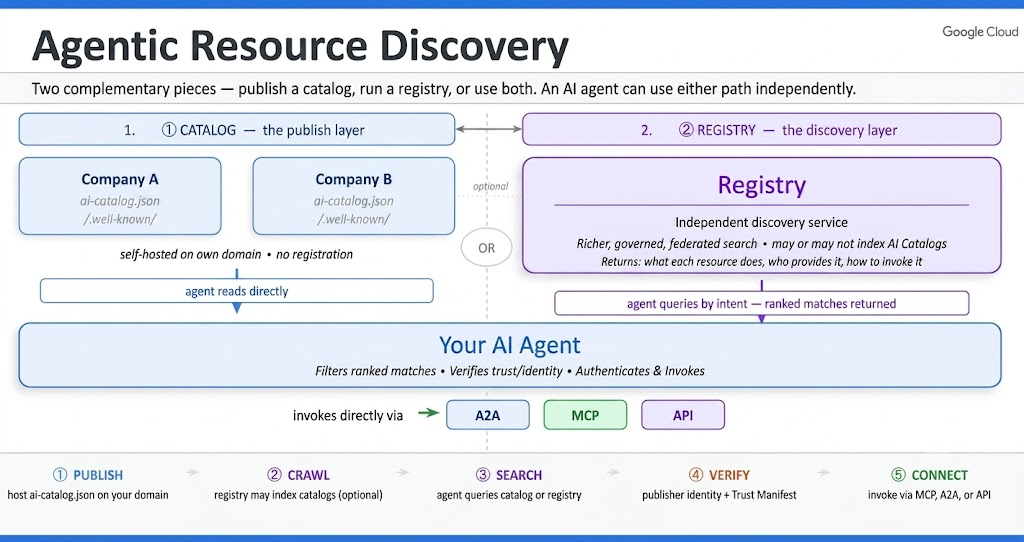
Technische Funktionsweise: Catalogs & Registries
Die ARD-Architektur beruht auf zwei tragenden Säulen, die das Vertrauens- und Suchmodell des agentischen Webs definieren:
- Catalogs (Kataloge): Jedes Unternehmen veröffentlicht eine maschinenlesbare Manifestdatei namens ai-catalog.json direkt auf der eigenen Domain unter einem standardisierten, geschützten Pfad. Da diese Datei auf Ihrem eigenen Webserver liegt, dient die Inhaberschaft der Domain als kryptografisches Fundament für Vertrauen und Identität.
- Registries (Register): Registries funktionieren wie Suchmaschinen für KI-Agenten. Sie crawlen das Web nach veröffentlichten ai-catalog.json-Dateien, indexieren deren Inhalte semantisch und machen sie über eine standardisierte API (z. B. POST /search) für anfragende KI-Clients durchsuchbar.
Quelle: https://developers.googleblog.com/announcing-the-agentic-resource-discovery-specification/
Die Struktur der ai-catalog.json: Das technische Datenmodell
Damit Registries und Agenten deine Schnittstellen fehlerfrei interpretieren können, muss die ai-catalog.json exakt nach der ARD-Spezifikation aufgebaut sein.
Ein kritischer Stolperstein in der Praxis ist die „Strict Value-or-Reference“-Bedingung des Katalogs: Ein Eintrag darf für seine technische Definition entweder nur das Feld url (Verweis auf eine externe Schnittstellendefinition) oder das Feld data (Direkteinbettung des Schemas) nutzen – niemals beide gleichzeitig.
Beispiel einer minimalen, validen ai-catalog.json für einen Antic Web Readiness Checker:
JSON
{
„specVersion“: „1.0“,
„host“: {
„displayName“: „Digital Loop“,
„identifier“: „did:web:digital-loop.com“
},
„entries“: [
{
„identifier“: „urn:ai:digital-loop.com:services:agentic-readiness-check“,
„displayName“: „Agentic Web Readiness Checker“,
„type“: „application/mcp-server+json“,
„url“: „https://api.digital-loop.com/mcp/agentic-check“,
„description“: „Analysiert Webseiten auf ihre Maschinenlesbarkeit (Machine-Readiness), ARD-Kompatibilität, strukturierte Metadaten (Schema.org) sowie das Vorhandensein von KI-Schnittstellen-Protokollen wie MCP.“,
„representativeQueries“: [
„Überprüfe ob meine Website für KI-Agenten lesbar ist“,
„Scanne meine Domain nach einer ai-catalog.json und ARD-Schnittstellen“,
„Analysiere die Machine-Readiness meiner B2B-Plattform“
],
„tags“: [„agentic-web“, „ard“, „machine-readiness“, „mcp“, „seo“]
}
]
}
Die wichtigsten Felder erklärt:
- identifier (Ebene Entry): Ein globally unique, domänenverankerter URN nach dem Schema urn:ai:<domain>:<namespace>:<name>. Er stellt sicher, dass Ihre Schnittstelle über alle weltweiten Register hinweg eindeutig identifizierbar bleibt, ohne dass es zu Namenskollisionen kommt.
- type: Der offizielle Medientyp der Ressource (z. B. application/mcp-server+json für MCP-Server oder application/a2a-agent-card+json für Agenten-zu-Agenten-Schnittstellen).
- representativeQueries: Das strategische Herzstück für Marketer. Hier werden 2 bis 5 natürlichsprachliche Fragen definiert, die genau beschreiben, bei welchen Aufgaben Ihr Tool helfen kann. Registries nutzen diese Phrasen als primäre Such- und Rankingfläche.
Wie machen wir unseren Katalog im Web sichtbar?
Damit dein Katalog von den Registries der großen Technologie-Plattformen (wie Googles Gemini Enterprise Agent Platform oder Microsofts Copilot) gecrawlt wird, definiert die ARD-Spezifikation drei komplementäre Signalkanal-Mechanismen:
Entdeckungsmechanismus | Technische Umsetzung | Strategische Funktion |
Well-Known URI | Bereitstellung der JSON-Datei exakt unter: https://domain.com/.well-known/ai-catalog.json [cite: 12] | Der primäre, standardisierte Abrufpfad für vertrauenswürdige Registry-Crawler und Partner-Agenten. [cite: 11] |
Robots.txt Directive | Hinzufügen der Zeile: Agentmap: https://domain.com/.well-known/ai-catalog.json in deiner robots.txt [cite: 12] | Erlaubt es konformen Crawlern, den Katalog sofort ohne Umwege über die Homepage direkt zu lokalisieren. [cite: 8] |
HTML Header Link | Einbindung von: <link rel=“ai-catalog“ href=“https://domain.com/.well-known/ai-catalog.json“> im HTML-<head> [cite: 12] | Signalisiert Web-Crawlern beim normalen Indexieren der Website die Existenz deines Agenten-Katalogs. [cite: 8] |
Governance & Operationalisierung: To-Dos für Unternehmen
KI-Implementierungen scheitern in der Praxis selten an der Technologie selbst, sondern an fehlenden Strukturen, unklaren Verantwortlichkeiten und mangelhafter Datendisziplin. Wenn autonome Systeme Ihre Daten crawlen, um Kaufentscheidungen zu treffen, müssen diese fehlerfrei und geschützt sein. Jedes zukunftsorientierte Unternehmen benötigt daher eine klare ARD-Governance.
Da technisch versierte SEO-Manager bzw. GAIO/AEO-Manager (Generative AI Optimization / Answer Engine Optimization) die übliche Arbeitsweise von Suchsystemen und Indexierungen bestens kennen, spielen sie hier eine zentrale Rolle.
Strategische Rollenverteilung:
- GAIO (Generative AI Optimization) Manager oder SEO Manager: Sie besitzen strategische Ownership. Sie definieren die fachlichen Anforderungen, prüfen die Relevanz der representativeQueries und steuern die Sichtbarkeit in den Registern.
- IT & Schnittstellen-Teams: Sie sind für die fehlerfreie Bereitstellung der Infrastruktur zuständig.
Ihre ARD-Checkliste zur Umsetzung:
- [ ] Cross-Functional Task Force gründen: Bringen Sie Marketing (GAIO/SEO), IT und ggf. Legal/Compliance an einen Tisch.
- [ ] Schnittstellen-Inventur durchführen: Erfassen Sie alle im Unternehmen existierenden Web-Schnittstellen, MCP-Server, kundenrelevanten APIs und Support-Bots.
- [ ] Endpunkte klassifizieren & selektieren: Definieren Sie strikt, welche APIs und Agentic-Endpunkte für Endkunden und deren Agenten nutzbar sein sollen. Private oder sensible interne Core-Systeme werden konsequent ausgeschlossen.
- [ ] ai-catalog.json programmieren: Generieren Sie die Manifestdatei unter Einhaltung des RFC-8141-URN-Schemas und der Strict-Value-or-Reference-Regel.
- [ ] Semantische Keyword-Optimierung: Optimieren Sie die representativeQueries im Katalog so, dass sie perfekt auf die typischen Suchabsichten moderner KI-Agenten passen.
- [ ] Sicherheit & Trust-Manifest einrichten: Hinterlegen Sie im optionalen trustManifest-Block Ihres Katalogs kryptografische Nachweise (wie DIDs oder SPIFFE IDs), um die Authentizität Ihres Unternehmens zweifelsfrei zu belegen.
- [ ] CORS- & Server-Konfiguration: Hosten Sie die Datei statisch unter der Well-Known URI ohne vorgeschaltete Authentifizierungshürden oder Bot-Sperren.
- [ ] Signale aktivieren: Implementieren Sie die Robots.txt-Direktive (Agentmap) und den HTML-Header-Link.
- [ ] Dauerhaftes Monitoring etablieren: Richten Sie automatisierte CI-Checks ein, um die Erreichbarkeit Ihres Katalogs und die Funktion der dahinterliegenden APIs kontinuierlich zu überwachen.
Jetzt herunterladen: ARD Implementierungs Checkliste
FAQ – Häufig gestellte Fragen zu ARD
Ersetzt ARD das klassische SEO?
Nein, es erweitert es. SEO optimiert für menschliche Nutzer, die über visuelle Oberflächen auf Suchergebnisse klicken. ARD optimiert für autonome KI-Systeme, die im Hintergrund eigenständig nach Services, Daten und Transaktionsmöglichkeiten suchen. Beide Disziplinen müssen komplementär betrieben werden.
Warum reicht das Model Context Protocol (MCP) allein nicht aus?
MCP standardisiert, wie ein Agent und ein Server miteinander sprechen. Es bietet jedoch keinen Mechanismus, über den ein Agent im Vorfeld dynamisch herausfinden kann, welche Server oder Dienste im Web überhaupt existieren. ARD ist die Discovery-Ebene (das Telefonbuch), die dem eigentlichen MCP-Verbindungsaufbau vorgeschaltet ist.
Müssen wir alle unsere APIs für den Katalog öffentlich machen?
Absolut nicht. Im Rahmen Ihrer internen Governance entscheiden Sie präzise, welche spezifischen Agentic- und API-Endpunkte für Endkunden freigegeben werden. Nur diese werden im öffentlichen Katalog gelistet. Vertrauliche Unternehmensdaten verbleiben hinter klassischen IT-Sicherheitsbarrieren.
In der Regel sind das Services und Schnittstellen, auf die Enduser bereits über eine Web-UI zugreifen (z. B. Produktsuchen oder Online-Rechner).
Was passiert, wenn wir ARD nicht implementieren?
Da KI-Assistenten und „Zero-Click-Szenarien“ immer häufiger direkte Antworten liefern oder Transaktionen eigenständig im Hintergrund abwickeln, sinkt der klassische Website-Traffic.
Wenn deine Angebote und Schnittstellen für Daten-Agenten nicht maschinenlesbar über ARD auffindbar sind, existiert Ihre Marke für diese Systeme schlichtweg nicht. Sie verlieren die Sichtbarkeit im modernen Web.
Nächster Schritt: Möchten Sie die Sichtbarkeit Ihrer Marke im Agentic Web sichern? Laden Sie hier unsere vollständige ARD-Implementierungs-Checkliste herunter oder kontaktieren Sie uns für eine strategische GAIO-Beratung.
Quellen:
- https://drive.google.com/open?id=1sh3b536rlmzUyaHwfRJHZvi4-GlfBrhcP5z53EW5SSk
- https://drive.google.com/open?id=1gqXyGHeWnZrqyi76Ojg7JuWq3_RtUUASKYoM7zMDKRM
- How the Agentic Resource Discovery specification helps agents find each other at enterprise scale – Outshift | Cisco, https://outshift.cisco.com/blog/ai-ml/agentic-resource-discover-specification-helps-agents-find-each-other
- AI agents are getting their own search engine | ZDNET, https://www.zdnet.com/article/ai-agents-are-getting-their-own-search-engine/
- Introducing the Agentic Resource Discovery specification – Command Line – Microsoft, https://commandline.microsoft.com/agentic-resource-discovery-specification-ard/
- Agentic Resource Discovery: Let agents search – Hugging Face, https://huggingface.co/blog/agentic-resource-discovery-launch
- Announcing the Agentic Resource Discovery specification – Google Developers Blog, https://developers.googleblog.com/announcing-the-agentic-resource-discovery-specification/
- Agentic Resource Discovery (ARD) & ai-catalog.json: The Complete Guide – Synscribe, https://www.synscribe.com/agentic-discovery/agentic-resource-discovery
- How to Implement the ARD Specification: A Step-by-Step Guide for SaaS Companies, https://www.synscribe.com/blog/how-to-implement-ard-specification-saas
- urn-naming-guide.md – ards-project/ard-spec – GitHub, https://github.com/ards-project/ard-spec/blob/main/spec/urn-naming-guide.md
- GitHub and Google back ARD standard for AI agent discovery, https://www.developer-tech.com/news/github-google-ard-ai-agent-discovery/
- Google’s open standard for AI agents to discover and verify tools – Help Net Security, https://www.helpnetsecurity.com/2026/06/18/google-agentic-resource-discovery/
- Agent finder for GitHub Copilot now available, https://github.blog/changelog/2026-06-17-agent-finder-for-github-copilot-now-available/


