Strukturierte Daten werden oft fälschlicherweise als taktische SEO-Maßnahme betrachtet, als Mittel zur Erzielung einfacher Rich Snippets. Diese Sichtweise ist im Zeitalter der KI-Suche überholt. Für Unternehmensmarken und Content-Plattformen, die in großem Maßstab operieren, sind strukturierte Daten zu einer semantischen Infrastruktur geworden. Sie ist unerlässlich für maschinenlesbare Klarheit, das Verständnis von Entitäten und die zuverlässige Inhaltsabfrage durch Large Language Models (LLMs) und generative Systeme. Wenn strukturierte Daten als architektonische Notwendigkeit implementiert werden, verdeutlichen sie komplexe Content-Ökosysteme. Sie stellen sicher, dass wichtige Informationen nicht nur für die traditionelle Suche sichtbar sind, sondern explizit strukturiert sind, um eine zuverlässige Synthese und Validierung in KI-Übersichten zu ermöglichen.
Informationen darüber, was strukturierte Daten sind und worin der Unterschied zwischen Schema-Markup und strukturierten Daten besteht, finden Sie im Artikel „Sichtbarkeit durch Schema Markup (strukturierte Daten) erhöhen“. |
Googles eigene Dokumentation untermauert dies und erklärt, dass strukturierte Daten „den Inhalt der betreffenden Seite“ beschreiben und somit praktisch als Übersetzungsschicht zwischen Inhalten und Suchsystemen fungieren.
Um zu verstehen, warum dies wichtig ist, ist es hilfreich, sich anzuschauen, wie sich die Suche selbst entwickelt hat.
Vom Keyword-Abgleich zum Verständnis von Entitäten
Frühe Suchmaschinen stützten sich in erster Linie auf lexikalische Übereinstimmungen.
Algorithmen werteten Schlüsselwörter, Ankertexte, Seitentitel und Linksignale aus, um die Relevanz zu bestimmen. Wenn eine Seite dem Wortlaut einer Suchanfrage nahe genug kam, wurde sie oft erfolgreich gerankt, auch wenn die tiefere Bedeutung unklar blieb.
Moderne Suchsysteme funktionieren anders.
Suchmaschinen versuchen zunehmend Folgendes zu verstehen:
- Entitäten
- Beziehungen
- Kontextuelle Bedeutung
- Thematische Zusammenhänge
- Reale Verbindungen zwischen Konzepten
Diese Entwicklung hat die Art und Weise grundlegend verändert, wie Suchsysteme Informationen verarbeiten.
Eine Seite über einen „Jaguar“ könnte sich auf ein Tier, eine Automarke oder eine Sportmannschaft beziehen. Der Text allein kann diese Mehrdeutigkeit manchmal auflösen, aber nicht immer. Strukturierte Daten liefern eindeutige Signale, die verdeutlichen, was die Seite tatsächlich beschreibt.
Strukturierte Daten erreichen das, indem sie maschinenlesbare Metadaten an Inhaltselemente anhängen. Diese Annotationen helfen Suchsystemen dabei, die Art des Inhalts zu identifizieren, den sie verarbeiten, und wie dieser mit anderen Entitäten im Web in Beziehung steht.
Schema-Vokabulare wie Schema.org ermöglichen es Publishern, Entitäten und Inhaltstypen in standardisierten Formaten zu beschreiben. Diese maschinenlesbaren Annotationen helfen Algorithmen zu verstehen, ob eine Seite Folgendes darstellt:
- Artikel
- Produkt
- Organisation
- Veranstaltung
- Finanzprodukt
- Oder eine andere strukturierte Entität
Diese Fähigkeit ist weit über Rich Snippets hinaus von Bedeutung.
Strukturierte Daten tragen zur Bildung von Wissensgraphen, zur Entitätserkennung und zur automatisierten Informationsverarbeitung bei. Sie helfen Suchsystemen zu verstehen, dass ein Artikel zu einem bestimmten Herausgeber gehört, dass ein Autor über Fachwissen zu einem Thema verfügt oder dass ein Produkt einen bestimmten Preis und eine bestimmte Verfügbarkeit hat.
Mit anderen Worten: Strukturierte Daten wandeln beschreibende Inhalte in strukturiertes Wissen um.
Dieses Bild wurde von KI generiert.
Warum strukturierte Daten bei großem Website-Umfang entscheidend werden
Je größer eine Website wird, desto schwieriger ist es für Suchsysteme, sie ohne explizite Signale korrekt zu interpretieren.
Kleine Websites haben dieses Problem selten. Ein Blog mit zehn Seiten, einem einzigen Autor und einem klaren thematischen Schwerpunkt lässt sich von Algorithmen relativ leicht interpretieren. Oftmals sorgt der Kontext allein für ausreichende Klarheit.
Große Websites bringen eine Komplexität mit sich, die durch einfache kontextuelle Interpretation nicht immer gelöst werden kann.
Ein großer Verlag veröffentlicht möglicherweise Hunderte von Artikeln pro Monat. Ein E-Commerce-Marktplatz kann Millionen von Produktseiten hosten. Unternehmen sind häufig gleichzeitig über mehrere Abteilungen, Inhaltstypen und Themenbereiche hinweg tätig.
Aus der Perspektive eines Suchmaschinen-Crawlers kann diese Umgebung chaotisch wirken.
Strukturierte Daten sorgen für Ordnung.
Anstatt Crawler zu zwingen, die Bedeutung allein aus dem Seitentext abzuleiten, beschreibt Schema-Markup explizit die Entitäten und Beziehungen innerhalb der Website-Architektur. Artikel können mit Autoren verknüpft werden. Produkte können mit Marken verknüpft werden. Organisationen können mit offiziellen Kontaktinformationen und verifizierten Profilen assoziiert werden.
Diese Verbindungen ermöglichen es Suchsystemen, eine kohärente Darstellung des Informationsökosystems der Website zu erstellen.
Ohne diese strukturierte Ebene laufen große Websites Gefahr, semantisch fragmentiert zu werden. Seiten mögen zwar existieren, doch ihre Beziehungen bleiben unklar.
Suchsysteme haben dann Schwierigkeiten, Autorität, Fachwissen oder thematische Strukturen zu identifizieren.
Strukturierte Daten als Grundlage für entitätsbasiertes SEO
Suchmaschinen stützen sich zunehmend auf die Erkennung von Entitäten statt auf einfache Keyword-Übereinstimmungen. Dieser Wandel ist eine tiefgreifende Veränderung in der Art und Weise, wie Suchsysteme Informationen verarbeiten.
Anstatt jede Seite einzeln zu interpretieren, versuchen Algorithmen nun, Netzwerke von Entitäten und Beziehungen im gesamten Web zu verstehen.
Strukturierte Daten spielen in diesem Prozess eine entscheidende Rolle.
Wenn eine Website Entitäten wie Organisationen, Autoren, Produkte oder Veranstaltungen klar definiert, können Suchmaschinen diese Entitäten mit umfassenderen Wissensgraphen verknüpfen. Diese Graphen dienen als strukturierte Darstellungen realer Beziehungen.
Vernachlässigen Sie das erweiterte Autorenschema nicht. Stellen Sie sicher, dass jeder Artikel ein detailliertes Person-Schema für den Autor enthält, das auf das Profil des Autors verweist. Erwägen Sie die Implementierung der Schematypen reviewedBy oder editor für Artikel. Dies hilft dabei, den Namen eines Redakteurs anzuzeigen, stärkt Glaubwürdigkeitssignale und vermeidet potenziell rechtliche Fragen, was für den Aufbau von Vertrauen wichtig ist.
Wenn ein Artikel beispielsweise ein „Person“-Schema für einen Autor enthält, kann dieser Autor mit anderen Veröffentlichungen, sozialen Profilen oder externen Referenzen verknüpft werden. Mit der Zeit entwickeln Suchmaschinen ein stärkeres Vertrauen in die Identität und die Fachkompetenz dieses Autors.
In ähnlicher Weise hilft das „Organization“-Schema Suchmaschinen dabei, den Herausgeber hinter einer Website zu verstehen. Diese Informationen werden besonders wichtig bei der Bewertung von Glaubwürdigkeitssignalen wie Markenbekanntheit oder Vertrauenswürdigkeit.
Weitere Informationen zur Bedeutung der E-E-A-T-Faktoren finden Sie im Artikel „E-E-A-T in der Praxis: Ein umsetzbarer Rahmen für den Aufbau von Vertrauen, Autorität und Rankings“ |
Ohne strukturierte Daten müssen diese Zusammenhänge indirekt abgeleitet werden. Mit strukturierten Daten werden sie explizit.
Dieser Unterschied verbessert die Zuverlässigkeit der Suchauswertung erheblich.
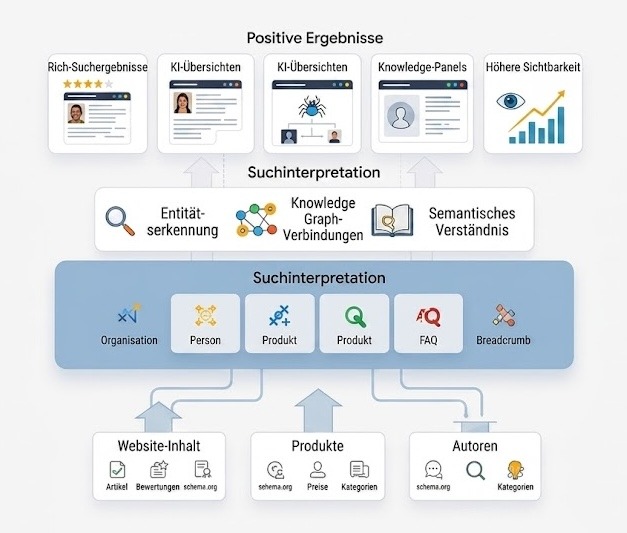
Strukturierte Daten und umfassende Sucherlebnisse
Strukturierte Daten werden oft mit umfassenden Suchergebnissen in Verbindung gebracht.
Beispiel für umfassende Suchergebnisse:
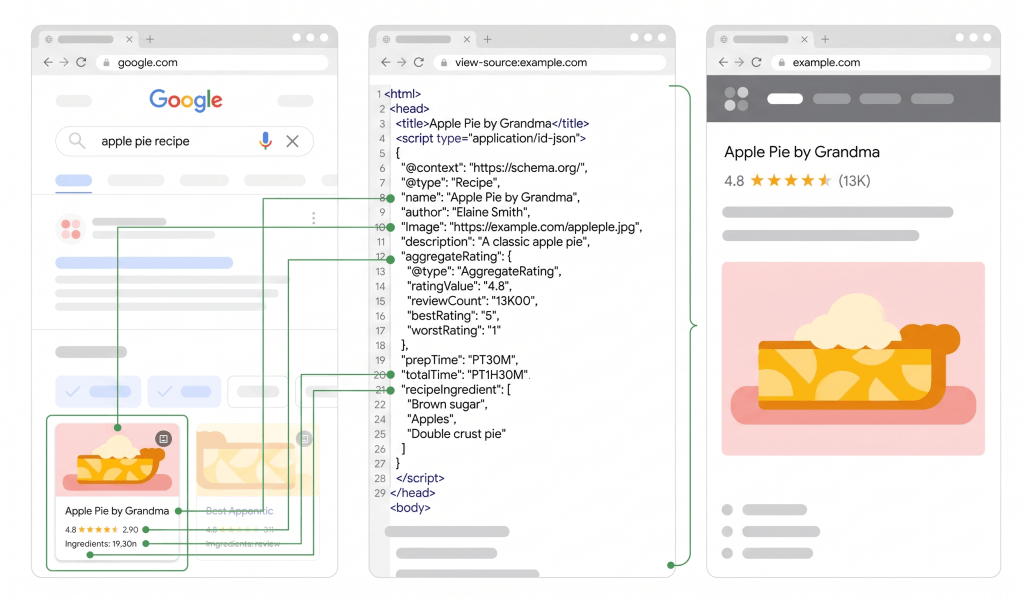
Quelle: https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
Rich Results vergrößern die visuelle Präsenz einer Seite in den Suchergebnissen. Sie bieten zusätzlichen Kontext wie Bewertungen, Preise, Veröffentlichungsdaten oder Antworten auf häufig gestellte Fragen direkt auf der Ergebnisseite.
Diese Verbesserungen können das Nutzerverhalten erheblich beeinflussen.
In Community-Diskussionen unter SEO-Experten wird häufig hervorgehoben, dass Schema-basierte Funktionen im Vergleich zu einfachen Ergebnissen mehr Platz einnehmen und die Klickraten verbessern. Ein Experte merkte an, dass Rich Snippets und FAQ-Schemas „einen großen Teil des mobilen Bildschirms einnehmen“ können, wodurch die Sichtbarkeit erhöht wird, während Konkurrenten weiter nach unten auf der Seite verdrängt werden.
Die Auswirkungen werden noch größer, wenn Websites in stark umkämpften Suchumgebungen konkurrieren.
Strukturierte Daten können darüber entscheiden, ob eine Seite mit erweiterten Informationen oder als reines Textergebnis angezeigt wird. Im Laufe der Zeit beeinflusst dieser Unterschied sowohl die Sichtbarkeit als auch die wahrgenommene Glaubwürdigkeit.
Für Unternehmenswebsites, die in großem Umfang auf organischen Traffic angewiesen sind, summieren sich diese kleinen Vorteile erheblich.
Strukturierte Daten und der Aufstieg der KI-Suche
Die Suche ist in eine neue Phase eingetreten, die von KI-gestützten Such- und generativen Antwortsystemen angetrieben wird.
Diese Systeme synthetisieren zunehmend Informationen aus mehreren Quellen, anstatt einfach nur auf einzelne Seiten zu verlinken. Um zuverlässige Antworten zu generieren, müssen sie strukturierte Informationen schnell interpretieren und validieren.
Strukturierte Daten tragen dazu bei, diese Klarheit zu schaffen.
Maschinenlesbare Markups ermöglichen es KI-gesteuerten Abrufsystemen, Folgendes zu identifizieren:
- Produktattribute
- Unternehmensinformationen
- Identität des Autors
- Metadaten zur Veröffentlichung
- Details zu Finanzprodukten
- Veranstaltungsinformationen
- Inhaltsbeziehungen
Infolgedessen liefern Websites mit starken strukturierten Daten oft sauberere Eingaben für KI-generierte Antworten und Wissenspanels.
Fallstudie für Unternehmen: Strukturierte Daten und Sichtbarkeit in KI-Übersichten
Bei einer unserer jüngsten Implementierungen haben wir die Auswirkungen des Hinzufügens des FinancialProduct-Schemas auf einer großen Finanzwebsite analysiert und über mehrere Monate hinweg Veränderungen der Sichtbarkeit in den Google-KI-Übersichten beobachtet.
Die Studie erfasste mehr als 1.000 Keywords über drei separate Zeiträume hinweg: vor der Implementierung, kurz nach der Bereitstellung und drei Monate später. Nach der Einführung der strukturierten Daten und der Indexierungsphase zeigte die Website einen messbaren Anstieg der Sichtbarkeit in den KI-Übersichten.
Das Überwachungs-Framework konzentrierte sich speziell auf die Sichtbarkeit innerhalb der Google-KI-Übersichten.
Nach der Einführung der strukturierten Daten und der Indexierungsphase:
- Die Erwähnungen der Marke in den AI-Übersichten stiegen um 8,58 %
- Die Anzahl der URLs, die in KI-generierten Antworten erschienen, stieg um 7,09 %
- Während etwa 66,7 % der wichtigsten Wettbewerber im gleichen Zeitraum einen Rückgang der Sichtbarkeit verzeichneten

Quelle: https://drops.digital-loop.com/i/xgzFf7
Diese Ergebnisse lassen nicht den Schluss zu, dass allein strukturierte Daten für die Verbesserungen verantwortlich waren. Die Sichtbarkeit in Suchmaschinen wird stets von mehreren Faktoren beeinflusst. Die Implementierung schien jedoch die Art und Weise zu verbessern, wie Suchsysteme das Finanzunternehmen interpretierten und die Marke mit relevanten, KI-generierten Antworten in Verbindung brachten.
Dieser Fall veranschaulicht einen umfassenderen Wandel in der modernen Suchmaschinenoptimierung (SEO). Bei strukturierten Daten geht es nicht mehr nur darum, Rich Snippets zu ermöglichen. Sie fungieren zunehmend als semantische Ebene, die KI-Systemen dabei hilft, Inhalte zu identifizieren, zu klassifizieren und in neuen Sucherlebnissen zuverlässig anzuzeigen.
Welche Arten strukturierter Daten sollten Unternehmenswebsites priorisieren?
Nicht alle Schema-Typen bieten den gleichen strategischen Wert.
Unternehmen sollten Markups priorisieren, die das Verständnis von Entitäten, die semantische Konsistenz und die Beziehungen zwischen Inhalten stärken.
Grundlegende Entitätsarchitektur
Diese Schema-Typen legen zentrale Identitätsmerkmale fest.
- Organisation
- Person
- WebSite
- WebPage
- Breadcrumb-Liste
Diese Entitäten helfen Suchsystemen zu verstehen, wer den Inhalt veröffentlicht, wer ihn erstellt, wie die Website strukturiert ist und wie Seiten hierarchisch miteinander verbunden sind.
Kerninhaltsverständnis
Diese Schematypen unterstützen die Interpretation primärer Inhaltsformate.
- Artikel
- Nachrichtenartikel
- Blogbeitrag
- Produkt
- FAQ-Seite
- Anleitung
- Videoobjekt
Diese Ebene verbessert die Klassifizierung und unterstützt eine optimierte Abfrage.
Branchenspezifische semantische Erweiterungen
Diese Schematypen gewinnen in spezialisierten Branchen besonders an Bedeutung.
Beispiele hierfür sind:
- Finanzprodukt,
- MedizinischeEinrichtung,
- Softwareanwendung,
- Kurs,
- Veranstaltung,
- Stellenanzeige,
- Rezept.
Diese Schemata bieten einen tieferen semantischen Kontext, der für branchenspezifische Suchsysteme relevant ist.
Die Priorisierungsstrategie sollte auf die Geschäftsziele, die Möglichkeiten zur Sichtbarkeit in Suchmaschinen und den Reifegrad der Entitätsarchitektur abgestimmt sein.
Die eigentliche Herausforderung: Die Implementierung von Schemata in großem Maßstab
Während die Vorteile strukturierter Daten klar sind, bringt ihre Implementierung auf großen Websites praktische Herausforderungen mit sich.
Viele Unternehmen beginnen mit manuellen Schema-Ergänzungen auf einzelnen Seiten. Dieser Ansatz wird schnell unhaltbar, wenn Websites Tausende von URLs enthalten.
Im großen Maßstab müssen strukturierte Daten automatisiert werden.
Content-Management-Systeme sollten Schemata dynamisch auf der Grundlage strukturierter Felder innerhalb des CMS generieren. Autorennamen, Veröffentlichungsdaten, Produktattribute und andere wichtige Eigenschaften sollten direkt in Markup-Vorlagen einfließen.
Automatisierung gewährleistet Konsistenz.
Konsistenz ist wichtig, da Suchsysteme bei der Interpretation strukturierter Daten auf Muster angewiesen sind. Wenn Schemata auf einer Website nur sporadisch vorkommen, werden ihre Signale schwächer und weniger zuverlässig.
Eine weitere Herausforderung betrifft die Datengenauigkeit.
Strukturierte Daten müssen stets den sichtbaren Inhalt einer Seite widerspiegeln. Bei Unstimmigkeiten wie veralteten Produktpreisen oder falschen Veröffentlichungsdaten ignorieren Suchmaschinen das Markup möglicherweise vollständig.
Strukturierte Daten müssen stets den sichtbaren Inhalt der Seite genau widerspiegeln, da Abweichungen dazu führen können, dass Suchmaschinen das Markup vollständig ignorieren.
Wenn Sie mehrere strukturierte Datenblöcke auf einer einzigen Seite implementieren (z. B. „Article“ und „FAQPage“), definieren Sie jeden Schematyp als separaten JSON-LD-Block auf oberster Ebene oder verwenden Sie die @graph-Struktur, um eine korrekte Interpretation durch Googles Rich Results Test und andere Tools sicherzustellen. Vermeiden Sie es, ein Schema (wie „FAQPage“) mithilfe von Eigenschaften wie „relatedLink“ in ein anderes (wie „Product“) einzubetten, da dies nicht die empfohlene Vorgehensweise ist.
Die Pflege eines korrekten Schemas erfordert daher eine kontinuierliche Überwachung.
Fazit
Bei großen Websites fungiert Schema-Markup als semantische Infrastrukturschicht, die Suchmaschinen dabei hilft, komplexe Inhaltsökosysteme zu verstehen. Es verdeutlicht Entitäten, stärkt Beziehungen zwischen Seiten und ermöglicht reichhaltigere Sucherlebnisse.
Da sich Suchsysteme zunehmend in Richtung KI-gestützter Abfrage, Synthese und entitätsbasierten Verständnisses entwickeln, gewinnt die maschinenlesbare semantische Architektur an Bedeutung.
Der Wettbewerbsvorteil beschränkt sich nicht mehr nur auf das Erreichen von Rich Results.
Er hängt zunehmend davon ab, ob Suchsysteme Informationen im gesamten Web zuverlässig interpretieren, verknüpfen, validieren und wiederverwenden können.
Unternehmen, die strukturierte Daten als Infrastruktur und nicht als isoliertes Markup betrachten, verschaffen sich einen erheblichen strategischen Vorteil in der modernen Suche.


