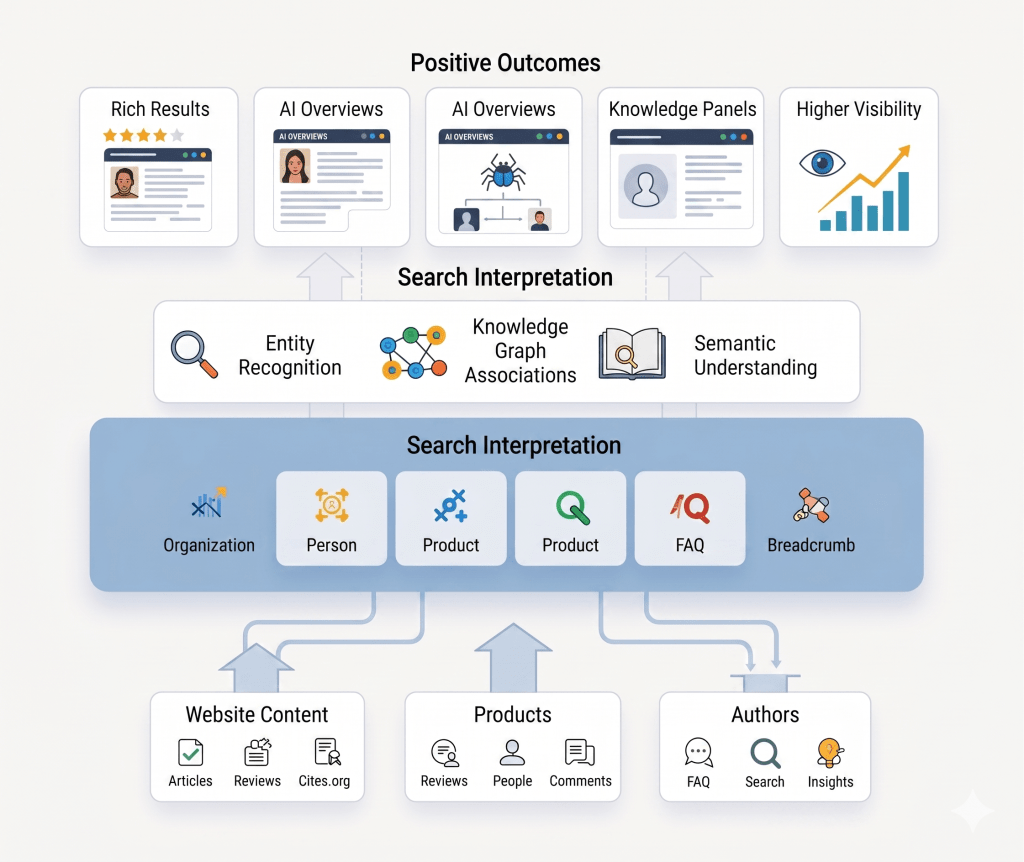
Structured data is often mistakenly viewed as a tactical SEO enhancement, a tool for achieving simple rich snippets. This perspective is obsolete in the era of AI Search. For enterprise brands and content platforms operating at scale, structured data has become the semantic infrastructure layer essential for machine-readable clarity, entity understanding, and robust content retrieval by Large Language Models (LLMs) and generative systems. When implemented as an architectural necessity, it clarifies complex content ecosystems, ensuring key information is not only visible to traditional search but is explicitly structured for confident synthesis and validation in the rising wave of AI Overviews.
For information on what structured data is and the difference between Schema Markup and Structured Data, read the article “How to Increase Visibility with Structured Data (Schema Markup)”. |
Google’s own documentation reinforces this, stating that structured data provides “explicit clues about the meaning of a page,” effectively acting as a translation layer between content and search systems.
To understand why this matters, it helps to look at how search itself has evolved.
From Keyword Matching to Entity Understanding
Early search engines primarily relied on lexical matching.
Algorithms evaluated keywords, anchor text, page titles, and link signals to determine relevance. If a page matched the wording of a query closely enough, it often ranked successfully even when deeper meaning remained unclear.
Modern search systems operate differently.
Search engines increasingly attempt to understand:
- Entities
- Relationships
- Contextual meaning
- Topic associations
- Real-world connections between concepts
This evolution fundamentally changed how search systems process information.
A page about a “jaguar” might refer to an animal, a car brand, or a sports team. Text alone can sometimes resolve this ambiguity, but not always. Structured data provides explicit signals that clarify what the page actually describes.
Structured data achieves this by attaching machine-readable metadata to content elements. These annotations help search systems identify the type of content they are processing and how it relates to other entities on the web.
Schema vocabularies such as Schema.org allow publishers to describe entities and content types in standardized formats. These machine-readable annotations help algorithms understand whether a page represents:
- Article
- Product
- Organization
- Event
- Financial product
- Or another structured entity
This ability matters far beyond rich snippets.
Structured data contributes to knowledge graph formation, entity recognition, and automated information extraction. It helps search systems understand that an article belongs to a specific publisher, that an author has expertise in a topic, or that a product has a specific price and availability.
In other words, structured data converts descriptive content into structured knowledge.
This image was generated by AI.
Why Structured Data Becomes Critical at Scale
The larger a website becomes, the harder it is for search systems to interpret it correctly without explicit signals.
Small sites rarely experience this problem. A ten-page blog with a single author and clear topic focus is relatively easy for algorithms to interpret. Context alone often provides sufficient clarity.
Large websites introduce complexity that simple contextual interpretation cannot always resolve.
A major publisher may produce hundreds of articles per month. An e-commerce marketplace might host millions of product pages. Enterprise organizations frequently operate across multiple departments, content types, and topic areas simultaneously.
From the perspective of a search engine crawler, this environment can look chaotic.
Structured data introduces order.
Instead of forcing crawlers to infer meaning from page text alone, schema markup explicitly describes the entities and relationships within the site architecture. Articles can be connected to authors. Products can be linked to brands. Organizations can be associated with official contact information and verified profiles.
These connections allow search systems to construct a coherent representation of the website’s information ecosystem.
Without this structured layer, large sites risk becoming semantically fragmented. Pages may exist, but their relationships remain unclear.
Search systems then struggle to identify authority, expertise, or topical structure.
Structured Data as the Foundation of Entity-Based SEO
Search engines increasingly rely on entity recognition rather than simple keyword matching. This shift reflects a deeper transformation in how search systems process information.
Instead of interpreting each page independently, algorithms now attempt to understand networks of entities and relationships across the web.
Structured data plays a critical role in this process.
When a website clearly defines entities, such as organizations, authors, products, or events, search engines can connect those entities to broader knowledge graphs. These graphs serve as structured representations of real-world relationships.
Don’t neglect the enhanced authorship schema. Ensure every article includes a detailed Person schema for the author, which links to the author’s profile. Consider implementing the reviewedBy or editor schema types for articles. This helps display an editor’s name, strengthening credibility signals and potentially avoiding legal questions, which is important for establishing trust.
For example, when an article contains a Person schema for an author, that author can be linked to other publications, social profiles, or external references. Over time, search engines develop stronger confidence in the identity and expertise of that contributor.
Similarly, Organization schema helps search engines understand the publisher behind a site. This information becomes particularly important when evaluating credibility signals such as brand recognition or trustworthiness.
For more information on the importance of E-E-A-T factors, see the article “E-E-A-T in Action: A Practical Framework for Building Trust, Authority, and Rankings” |
Without structured data, these connections must be inferred indirectly. With structured data, they become explicit.
This distinction significantly improves the reliability of search interpretation.
Structured Data and Rich Search Experiences
Structured data is often associated with rich search results.
Example of reach results:
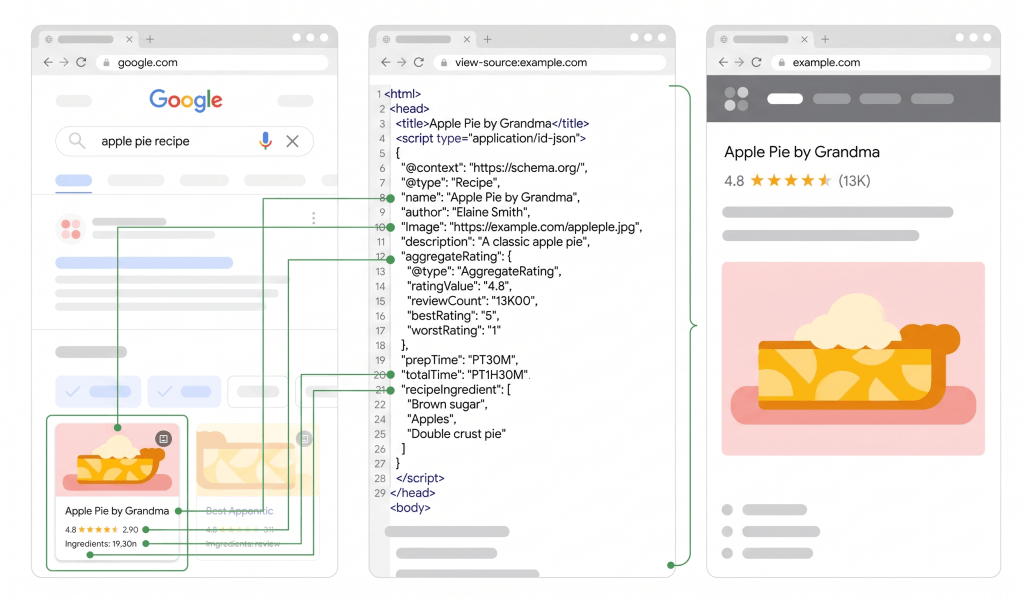
Source: https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
Rich results expand the visual footprint of a page in search listings. They provide additional context, such as ratings, prices, publication dates, or FAQ answers, directly within the results page.
These enhancements can significantly influence user behavior.
Community discussions among SEO practitioners frequently highlight that schema-enabled features occupy more visual space and improve click-through rates compared to plain results. One practitioner noted that rich snippets and FAQ schema can “take up a huge chunk of mobile screens,” increasing visibility while pushing competitors further down the page.
The impact becomes even greater when websites compete in highly competitive search environments.
Structured data can determine whether a page appears with enhanced information or as a simple text result. Over time, this difference influences both visibility and perceived credibility.
For enterprise websites that depend on organic traffic at scale, these small advantages compound significantly.
Structured Data and the Rise of AI Search
Search has entered a new phase driven by AI-assisted discovery and generative answer systems.
These systems increasingly synthesize information from multiple sources rather than simply linking to individual pages. To generate reliable answers, they must interpret and validate structured information quickly.
Structured data helps provide that clarity.
Machine-readable markup allows AI-driven retrieval systems to identify:
- Product attributes
- Business information
- Author identity
- Publication metadata
- Financial product details
- Event information
- Content relationships
As a result, websites with strong structured data often provide cleaner inputs for AI-generated answers and knowledge panels.
Enterprise Case Study: Structured Data and AI Overview Visibility
In one of our recent implementations, we analyzed the impact of adding FinancialProduct schema across a large financial website and monitored visibility changes in Google AI Overviews over several months.
The study tracked more than 1,000 keywords across three separate periods: before implementation, shortly after deployment, and three months later. After the structured data rollout and indexation period, the site showed a measurable increase in AI Overview visibility.
The monitoring framework focused specifically on visibility within Google AI Overviews.
After the structured data rollout and indexation period:
- Brand mentions in AI Overviews increased by 8.58%
- The number of URLs appearing in AI-generated responses increased by 7.09%
- While approximately 66.7% of key competitors experienced visibility declines during the same period

Source: https://drops.digital-loop.com/i/xgzFf7
These results do not suggest that structured data alone caused the gains. Search visibility is always influenced by multiple factors. However, the implementation appeared to strengthen how search systems interpreted financial entities and associated the brand with relevant AI-generated responses.
The case illustrates a broader shift in modern SEO. Structured data is no longer just about enabling rich snippets. It increasingly acts as a semantic layer that helps AI systems identify, classify, and confidently surface content in emerging search experiences.
Which Structured Data Types Enterprise Websites Should Prioritize
Not all schema types deliver equal strategic value.
Enterprise organizations should prioritize markup that strengthens entity understanding, semantic consistency, and content relationships.
Foundational Entity Architecture
These schema types establish core identity signals.
- Organization
- Person
- WebSite
- WebPage
- BreadcrumbList
These entities help search systems understand who publishes the content, who creates it, how the website is structured, and how pages connect hierarchically.
Core Content Understanding
These schema types support interpretation of primary content formats.
- Article
- NewsArticle
- BlogPosting
- Product
- FAQPage
- HowTo
- VideoObject
This layer improves classification and supports enhanced retrieval.
Vertical-Specific Semantic Enhancements
These schema types become especially important in specialized industries.
Examples include:
- FinancialProduct,
- MedicalEntity,
- SoftwareApplication,
- Course,
- Event,
- JobPosting,
- Recipe.
These schemas provide deeper semantic context relevant to industry-specific search systems.
The prioritization strategy should align with business objectives, search visibility opportunities, and entity architecture maturity.
The Real Challenge: Implementing Schema at Scale
While the benefits of structured data are clear, implementing it across large websites introduces practical challenges.
Many organizations begin with manual schema additions to individual pages. This approach quickly becomes unsustainable when sites contain thousands of URLs.
At scale, structured data must be automated.
Content management systems should generate schema dynamically based on structured fields within the CMS. Author names, publication dates, product attributes, and other key properties should feed directly into markup templates.
Automation ensures consistency.
Consistency is important because search systems rely on patterns when interpreting structured data. If schema appears only sporadically across a site, its signals become weaker and less reliable.
Another challenge involves data accuracy.
Structured data must always reflect the visible content on a page. When discrepancies occur, such as outdated product prices or incorrect publication dates, search engines may ignore the markup entirely.
Structured data must always be an accurate reflection of the visible content on the page, as discrepancies may lead search engines to ignore the markup entirely.
When implementing multiple structured data blocks on a single page (e.g., Article and FAQPage), define each schema type as a separate top-level JSON-LD block or use the @graph structure to ensure proper interpretation by Google’s Rich Results Test and other tools. Avoid nesting one schema (like FAQPage) inside another (like Product) using properties like relatedLink, as this is not the recommended setup.
Maintaining accurate schema, therefore, requires ongoing governance.
Conclusion
For large websites, schema markup functions as a semantic infrastructure layer that helps search engines understand complex content ecosystems. It clarifies entities, strengthens relationships between pages, and enables richer search experiences.
As search systems increasingly evolve toward AI-assisted retrieval, synthesis, and entity-based understanding, machine-readable semantic architecture becomes more important.
The competitive advantage is no longer limited to gaining rich results.
It increasingly depends on whether search systems can confidently interpret, connect, validate, and reuse information across the web.
Enterprise organizations that treat structured data as infrastructure rather than isolated markup gain a significant strategic advantage in modern search.