Implementing Large Language Models (LLMs) in enterprise environments is not only a technological challenge, it is a challenge of quality. Every word a model generates can impact user trust, brand reputation, and ultimately, business outcomes.
In traditional software projects, QA (Quality Assurance) ensures that requirements are met and defects are minimized. With LLMs, the rules change: the focus shifts from verifying code to validating meaning, context, and alignment with business goals. Without a solid QA strategy, even the most advanced LLMs can fail in ways that directly affect revenue, compliance, or customer satisfaction.
This guide outlines practical strategies to ensure quality in LLM implementations, while highlighting why QA is indispensable to transforming AI innovation into real business value.
Why QA is Essential for LLM Implementations
LLMs are powerful but unpredictable. A chatbot that answers quickly yet provides misleading, biased, or brand-inconsistent responses is not just a technical flaw—it’s a business risk.
Here is where QA comes. QA ensures that LLM outputs are:
- Factually accurate, reducing the risk of misinformation.
- Relevant to user queries, improving usability and trust.
- Consistent with the company’s tone and brand voice.
- Free from harmful or biased language, avoiding legal and reputational risks.
QA is the safeguard that turns experimentation with AI into enterprise-grade solutions.
Proceeding in this article, we’ll dive deeper into the main characteristics, tools, elements, and strategies that concern QA in LLM implementations from an all-around perspective, for a more detailed understanding.
Key Pillars of QA for LLMs
Let’s start from a practical example: consider an online education platform using an LLM to support students with explanations of complex topics. If the model delivers an inaccurate explanation of a math formula or provides biased historical interpretations, the impact goes beyond a simple error: it can mislead learners, undermine the platform’s credibility, and even affect academic performance. QA ensures that responses are factually accurate, pedagogically appropriate, aligned with the institution’s teaching style, and inclusive, protecting both learning quality and brand trust.For this reason, when defining quality in LLMs, four key pillars must be considered:
- Integrity and Factual Accuracy - Ensure responses are correct and free of hallucinations.
- Relevance - Responses must directly address the user’s intent, not just provide generic information.
- Brand Voice and Tone - Outputs should reflect the company’s identity, whether it is formal, empathetic, or technical.
- Bias and Fairness - Content must remain inclusive, neutral, and free of discriminatory undertones.
If any of these pillars fail, the consequences can be immediate: loss of user trust, reputational damage, or even compliance issues.
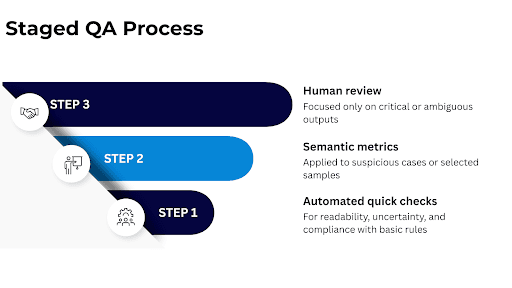
A Staged QA Process for Scalability
One of the biggest mistakes in LLM QA is trying to manually validate everything.
How to do it better and more effectively? Design a staged process:
- Automated quick checks: for readability, uncertainty, and compliance with basic rules.
- Semantic metrics: applied to suspicious cases or selected samples.
- Human review: focused only on critical or ambiguous outputs.
This staged approach ensures broad coverage while keeping QA costs under control.
Metrics that Really Matter
Another fundamental to consider is the metrics.
Not all metrics add equal value. The choice depends on budget, time, and business objectives:
- Lexical Metrics (ROUGE, BLEU): Measure word overlap between outputs and reference responses.
- Semantic Metrics (BERTScore, RAGAS): Evaluate meaning and faithfulness to context, which is often more relevant in enterprise use cases.
The goal is not to measure everything, but to prioritize metrics that reflect what “quality” means for the business.
Qualitative Evaluation for Strategic Value
Numbers alone cannot capture everything. QA also needs to assess qualitative aspects:
- Brand Voice: Use a brand voice document as a reference for tone, wording, and examples.
- Sentiment and Tone: Apply classifiers to check if content is formal, empathetic, or neutral.
- Readability: Validate that content matches the reading level of the target audience.
A model can be technically correct but still generate content that feels off-brand or disengaging.
The LLM-as-a-Judge Approach
One effective strategy to take into account is using an LLM to evaluate another LLM’s outputs.
How? It can be done in three ways:
- Asking for a score on a single response.
- Comparing two responses and selecting the better one.
- Measuring faithfulness against a reference answer (the most reliable method).
This approach enables automated, scalable QA for fidelity, relevance, and consistency… but be careful! It requires well-designed prompts and continuous calibration of the evaluator model.
Tools and Frameworks for QA in LLMs
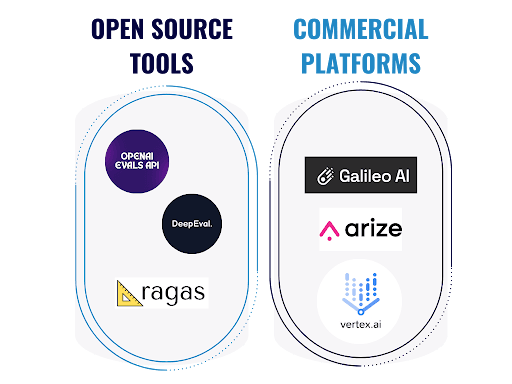
When it comes to tools and frameworks, various options are valuable and need to be chosen carefully. Depending on resources, companies can adopt:
- Open source tools: such as OpenAI Evals, DeepEval, RAGAS.
- Commercial platforms: such as Galileo AI, Arize AI, Vertex AI Evaluation.
For example, using RAGAS in Python allows measurement of three key semantic metrics:
- Faithfulness—checks factual consistency with the source.
- Answer Relevancy—evaluates alignment with the original question.
- Semantic Similarity—compares outputs with golden datasets.
Conclusion: QA as the Business Enabler for AI
Implementing LLMs in enterprises is not just about technology— it’s about trust. QA is what transforms an unpredictable model into a reliable business tool. With the right QA strategy, enterprises can confidently deploy LLMs, knowing they will deliver accurate, relevant, brand-aligned, and risk-free experiences to users.
In short: QA is not an optional checkpoint, it is the indispensable bridge between AI innovation and real business value.