Das Thema des „Cookieless“ Trackings beschäftigt uns nun schon eine ganze Weile. Während zahlreiche Interpretationen und Kontexte geboten werden, scheint es ziemlich schwierig zu verstehen, worum es hierbei eigentlich geht. Im folgenden Beitrag möchte ich kurz erläutern, was sich hinter dem „cookieless“-Tracking verbirgt und welchen Nutzen es für Ihre Messstrategie hat (oder nicht hat).
Inhalt:
- Was ist Cookieless Tracking?
- Wie wirkt es sich auf die Genauigkeit und Messung meiner Daten aus?
- Was cookiefreies Tracking nicht ist
- Übersicht
Was ist Cookieless Tracking?
Cookieless Tracking ist eine anonyme Methode zur Erfassung von Informationen über Besuche und Interaktionen mit Ihrer Website, ohne die Notwendigkeit, Daten zur Identifikation der Nutzer zu speichern. Da die gängigste Methode im Web 2.0 darin besteht, solche Informationen in Form von Cookies zu speichern, kommt auch der Name dieser Form zustande.
Wie Sie vielleicht schon wissen, sind Cookies kleine Textdateien, die in Ihrem Browser/Computer gespeichert werden. Sie können alle möglichen Informationen enthalten: von einem Timestamp, zu dem Sie Ihre Lieblingssendung angehalten haben, bis hin zum ersten Marketingkanal, über den Sie auf eine Website gelangt sind. Im Zusammenhang mit der Datenverfolgung enthalten Cookies jedoch sehr oft Kennungen (z. B. Benutzer-ID, Kunden-ID usw.), die zu einzelnen Nutzern zurückverfolgt werden können. Die schlechte Nachricht ist, dass solche Kennungen nach der Datenschutz-Grundverordnung als personenbezogene Daten gelten und die Zustimmung des aktiven Nutzers erfordern, was wiederum die Menge der erfassten Daten stark einschränkt und sich somit auf die Genauigkeit der Berichterstattung und Analyse auswirkt.
Die Idee des Cookieless Trackings ermöglicht es Ihnen, die Verwendung von Cookies mit personenbezogenen Daten und Benutzeridentifikatoren zu vermeiden. In bestimmten Fällen ist es auch möglich, das Tracking ohne eine aktive Zustimmung durchzuführen. Bevor wir uns die Vorteile und Grenzen einer solchen Tracking-Methode ansehen, sollten wir uns darüber im Klaren werden, wie sie aus technischer Sicht tatsächlich funktioniert.
Nachfolgend meine schlichte Illustration der Funktionsweise einer cookielosen Technologie im Vergleich zu, sagen wir, standardmäßigem clientseitigem Tracking in einem Marketingkontext.
Warnung für meine Web-Analysten-Kollegen: Es ist übertrieben vereinfacht
Standard-Client-Side-Tracking-Architektur unter Verwendung eines Tag-Management-Systems
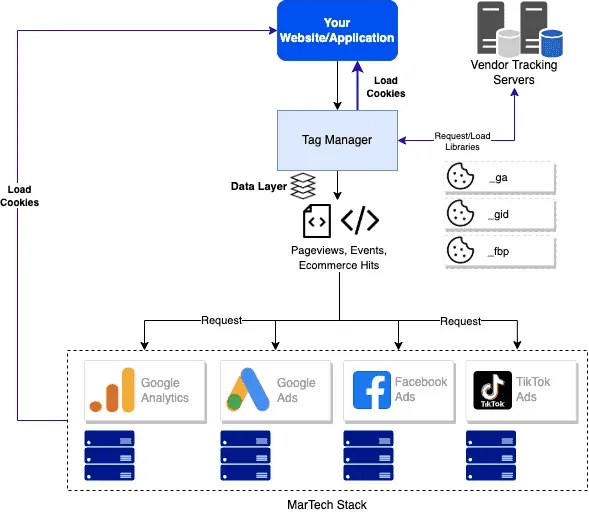
Wenn Ihre Website oder Anwendung vollständig gebootet/gerendert ist, wird ein Aufruf an die Tag-Management-Lösung Ihrer Wahl gemacht. Der Tag-Manager wiederum lädt die konfigurierten Tracking-Bibliotheken, die häufig Cookies mit Benutzerkennungen setzen. Nachdem bestimmte Interaktionen (wie Seitenaufrufe, Scrollen, Abspielen von Videos, Klicks usw.) auf Ihrer Website durchgeführt wurden, übermittelt der Tag-Manager die entsprechenden Treffer an die Server des Anbieters, die als Antwort zusätzliche Cookies setzen können (in der Regel im Kontext eines Dritten)
Cookieless Client-Side Tracking Architektur mit einem Tag Management System
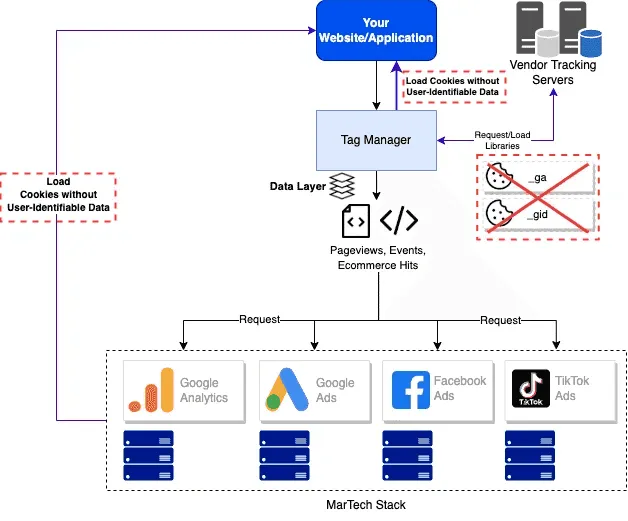
Wie Sie sehen, ähnelt der „cookieless“ Datenfluss dem standardmäßigen client-seitigen Tracking-Fluss, mit der Ausnahme, dass keine benutzerspezifischen Cookies verwendet werden – wobei sowohl Erst- als auch Drittanbieter-Cookies daran gehindert werden können, sich in Ihrem Browser einzunisten. Genau diese scheinbar kleine Änderung macht einen großen Unterschied bei der Verarbeitung solcher Daten.
Achtung: Bestimmte Browser (wie Safari oder Brave) können Cookies von Drittanbietern bereits standardmäßig blockieren oder ausschalten, ohne dass Sie als Benutzer*in etwas dafür tun müssen. Solche Browser verwenden intelligente Mechanismen zur Verhinderung von Tracking (ITP), um Cookies von Dritten entweder zu blockieren, zu begrenzen oder nach Ablauf einer bestimmten Zeit zu löschen. Ich empfehle Ihnen dringend, sich mit diesem Thema vertraut zu machen und immer die neuesten Updates zu verfolgen. Wenn Sie eine zuverlässige und messbare Webanalyselösung entwickeln wollen, ist es wichtig zu verstehen, wie sich solche Mechanismen wie ITP auf Cookies auswirken.
Und nun? Wie wirkt sich dies auf die Genauigkeit meiner Daten und die Messung aus?
Während wir alle Interaktionen wie Seitenaufrufe, Klicks, benutzerdefinierte Ereignisse und andere Arten von Treffern übermitteln, fügen wir diesen Anfragen einen wichtigen Parameter genau nicht hinzu – eine Benutzerkennung. Ohne eine Benutzerkennung können wir nicht zuverlässig sagen, ob Hit A und Hit B zum selben Benutzer gehören oder ob mehrere Sitzungen (d. h. verschiedene Sammlungen solcher Hits, die innerhalb eines einzigen Besuchs stattfanden) zur selben Person gehören. Was übrig bleibt, ist ein Pool von Ereignissen, die keinem Nutzerprofil zugeordnet werden können, was es extrem schwierig (oder sogar unmöglich) macht, Segmente zu erstellen, über Sitzungen hinweg zu verfolgen und eine realistische Nutzerzahl zu erhalten.
Es ist, als stünden wir auf einem Parkplatz voller Autos ohne Nummernschilder. Wir können die Abmessungen, Farben und Marken der Autos sehen, aber wir wissen nichts über ihre Herkunft und Zulassung, geschweige denn können wir ihre Besitzer identifizieren.
Andererseits können Sie die Reaktionen auf Ihre Anwendungen und Websites mit sehr geringen Datenlücken (d. h. Realität vs. Verfolgung) nachverfolgen und dabei die Privatsphäre und Anonymität der Nutzer vollständig respektieren. Und warum? Weil die Nachverfolgung ohne Benutzerkennungen oft als anonym gilt und möglicherweise keine Zustimmung in Form von Cookie-Bannern erfordert. Natürlich müssen Sie auch andere datenschutzrelevante Faktoren berücksichtigen, wie z. B. die Anonymisierung von IP-Adressen, die Speicherung der Daten am richtigen Ort (geografisch) und andere Faktoren, die sich nach Ihren lokalen Datenschutzgesetzen richten.
Dadurch stehen Ihnen verschiedene nicht-nutzer- und nicht-sitzungsbezogene KPIs zur Verfügung. Dies ermöglicht die Durchführung grundlegender Analysen wie Traffic- und Produktleistung, Seitenanalyse, Referrer- und Last-Click-Attributionsanalyse oder sogar eine Pathing-Analyse (wenn Sitzungs-IDs implementiert sind). Andere Arten von Web-Analysetechniken, die sich auf Nutzer und Sitzungen beziehen (wie Kohortenanalyse, Nutzersegmentierung, Attributionsmodellierung und andere), werden Ihnen nicht zur Verfügung stehen.
Letztendlich ist der Mangel an Nutzerdaten der Preis, den man zahlen muss, um mehr Interaktionen verfolgen zu können, auch wenn man dafür Abstriche bei der Qualität und den Analysemöglichkeiten in Kauf nimmt.
Was Cookieless Tracking nicht ist
Heutzutage wird der Begriff „cookieless“ in verschiedenen Zusammenhängen zweideutig verwendet. Auch wenn es einen gewissen Spielraum für Interpretationen gibt, ist es wichtig zu verstehen, was cookieless Tracking nicht ist.
“Cookieless“ bedeutet nicht das völlige Fehlen von Cookies, sondern das Fehlen von Cookies mit nutzeridentifizierbaren Daten.
Cookieless bezieht sich nicht nur auf Cookies an sich, sondern auch auf andere Formen der Browser-Speicherung, zum Beispiel das localStorage-Objekt. Das heißt, Sie können nicht einfach benutzeridentifizierbare Daten in solchen Browser-Speicherobjekten speichern und Ihre Einrichtung „cookieless“ nennen.
Oft wird Cookieless-Tracking in einem Server-Side-Kontext verwendet (d.h. Server-zu-Server-Kommunikation anstelle von Client-zu-Server), aber das ist nicht immer der Fall. Cookieless Tracking kann auch mit clientseitigen Komponenten verwendet werden, wenn Sie noch Tracking-SDKs oder -Bibliotheken laden, ohne Cookies zu setzen. Zum Beispiel die Consent Mode-Technologie von Google, die es Ihnen ermöglicht, Cookieless Pings zu senden, was die Genauigkeit der Datenmodellierung verbessert.
Zusammenfassung
Letztendlich ist das Tracking ohne Cookies ein großer Schritt hin zu einer besseren Welt der datenschutzfreundlichen Webanalyse. Außerdem wird das Web dadurch sicherer, da Cookie-Leaks und andere unheimliche JavaScript-Hacks vermieden werden können.
Bislang sind die sofort einsatzbereiten cookielosen Technologien noch weit davon entfernt, die gleiche Datenqualität zu liefern wie das Cookie-basierte Tracking. In der sich ständig verändernden Welt des Datenschutzes erwarte ich, dass mehr und mehr MarTech-, AdTech- und Webanalyse-Anbieter neue Technologien entwickeln, die die Cookie-Ära beenden und das Nutzererlebnis verbessern, den Datenschutz sicherer und die Prozesse transparenter machen.