When GPT (Generative Pre-trained Transformer) first landed in marketing teams, it felt like someone had handed us a caffeine-powered intern who never sleeps, never complains, and confidently answers everything. Copy? Done. Summaries? Easy. Strategy brainstorm? Absolutely. With bullet points. And emojis. Lots of emojis… Wow!
For a moment, it was pure magic.
Then the cracks appeared. GPT started inventing sources, confidently misreading numbers, and explaining our own products back to us… incorrectly. And too confidently. Nothing quite kills executive trust like an AI saying something wrong with the enthusiasm of a keynote speaker.
The problem was that we treated a language model like a marketing system, a secret ingredient in our marketing recipes that was supposed to make our prospects (and us) happy.
But the truth was bitter: GPT-style models are brilliant at producing plausible language, not grounded truth. They don’t know what your CRM says today, what your analytics looked like this morning, or which numbers Legal signed off on yesterday. Theypredict text. They don’t validate reality.
And misconceptions came up one after another:

The post took off. 500+ likes, over 400 comments, and plenty of love. SEOs, however, were not impressed…
Marketing reality is messy. Data lives in too many tools, changes constantly, and comes with consequences when it’s wrong. A hallucinated joke is funny. A hallucinated KPI in a board deck is career-limiting. That’s when the industry started to sober up.
The real shift happening right now isn’t from “bad prompts” to “better prompts.” It’s from language generation to decision-ready systems. Systems that know where data comes from, how fresh it is, what it’s allowed to say, and what should happen next once an answer is produced.
In enterprise environments (and beyond), AI doesn’t just need to sound smart. It needs to be:
- traceable
- auditable
- compliant
- repeatable
- and ideally… correct (which should be placed in the first place)
GPT is a fantastic “brain”. Marketing, however, needs “a full nervous system”, meaning that without “nerves” or marketing data, the “brain” or GPT has no awareness of the world around it.
The “nervous system” connects the “brain” to real marketing data, checks signals before reacting, and prevents confident nonsense from reaching customers, executives, or regulators. This is exactly where architectures like RAG, agents, and agentic workflows enter the picture.
Let’s jump into a brave new world where hallucinations are rather museum artifacts than production realities.
In this article, you will learn:
- Why GPT alone hits a hard ceiling in enterprise marketing
- What RAG actually fixes (and what it doesn’t)
- How AI agents turn answers into actions
- Why “agentic RAG” is not a buzzword but a structural upgrade
- When fine-tuning and LoRA make sense (and when they absolutely don’t)
- How to think about AI architecture choices like a system designer, not a prompt engineer
The Marketing Data Reality Check
Before talking about architectures, models, or anything with the word “agentic” in it, I need to do something slightly uncomfortable: look at what marketing data actually looks like in real enterprise environments.
Spoiler alert: it does not look like a clean CSV file waiting politely for an AI to analyze it. Enterprise marketing data lives everywhere at once.
- CRM systems with half-filled fields…
- Analytics platforms arguing with each other about attribution…
- SEO datasets measured in millions of keywords…
- Content libraries that haven’t been cleaned since the last rebrand…
- PR mentions scattered across news sites, forums, and social platforms…
- Product feeds updated daily…
- Legal constraints sitting quietly in the background, ready to shut everything down at the worst possible moment…
And all of this changes… constantly. Marketing data is not static knowledge. It’s a moving target with opinions.
This is exactly where GPT-style models start to struggle. They are trained on snapshots of the internet from the past. They don’t know what your conversion rate did yesterday, which campaign Legal approved this morning, or which product feature is no longer allowed to be mentioned in Germany but is perfectly fine in Spain.
Static models fail in dynamic environments because they have no sense of now. They generate answers as if time, context, and responsibility were optional.
The cost of a wrong answer here is not theoretical. It’s practical and painful:
- Wrong targeting means wasted media spend
- Wrong insights lead to bad strategic decisions
- Outdated messaging creates brand inconsistency
- Hallucinated facts can escalate into reputational or legal risk (did you hear about that famous failure of a well-known consulting firm? Just check this source than: https://fortune.com/2025/10/07/deloitte-ai-australia-government-report-hallucinations-technology-290000-refund/)
This is the point where RAG (Retrieval Augmented Generation) enters the story…
Evergreen Overview of Core AI Components (Conceptual Map)
It is dangerously easy to mix up terms and accidentally believe you have a system when you really just have a very confident autocomplete.
This section is a glossary, but more importantly, it is also a way to stop marketing, IT, and leadership from talking past each other while all using the same buzzwords.
LLMs (Large Language Models)
Let’s start with the foundation.
LLMs are extremely good at one thing: predicting the next token in a sequence based on probability. That’s it. Everything else is a side effect of doing that one thing at a massive scale.
They shine when the task is fuzzy, creative, or exploratory. If you need ten ways to explain a concept, rewrite a paragraph, or brainstorm angles for a campaign, LLMs are fantastic.
What they are not designed for:
- Knowing what is true right now
- Validating facts against live systems
- Understanding business rules or compliance constraints
- Taking responsibility for decisions
LLMs do not have access to your (or any) data unless you explicitly give it to them. They do not know which source is correct. They do not know when they are wrong. And they absolutely do not know when an answer could get you in trouble.
This is why “just use a bigger model” rarely delivers better business outcomes. Bigger models are better at language, not accountability. The truth is, they hallucinate more fluently, not more accurately.
GPT as an Interface, Not a System
GPT is best understood as an interface to language intelligence, not a marketing system. It’s a conversational layer that sits on top of a model and makes interaction easy for humans. That’s why it spread so fast.
No training. No onboarding. Just type and go.
As an interface, GPT is excellent at:
- Ideation and brainstorming
- Drafting content
- Summarizing long documents
- Acting as a thinking partner
It lowers the friction between humans and complex models, which is a massive achievement. But structurally, GPT has serious limitations for marketing data work. It has no built-in understanding of your internal data sources, data freshness, data ownership, approval workflows, brand or legal constraints, and much more…
In other words, GPT is great at talking about marketing. But it is not designed to run marketing.
Retrieval-Augmented Generation (RAG): The First Real Leap
At some point, every serious marketing team hits the same realization: the problem isn’t that the model can’t talk. The problem is that it doesn’t know our stuff.
This is the moment when AI stopped being a clever parrot and started behaving more like a junior analyst, who is at least required to check the documents before answering.
What RAG Actually Solves
Instead of asking the model to answer from its training data and vague memory of the internet, you force it to:
- Retrieve relevant information from your own trusted sources.
- Generate an answer based on that information.
This changes three things immediately.
First, grounding.
Answers are anchored in real, up-to-date data: your CRM exports, analytics reports, content libraries, product documentation, PR mentions, or internal guidelines. The model is no longer guessing what your brand sounds like. It is literally reading it.
Second, hallucination reduction.
Hallucinations don’t disappear entirely (please, read it again), but they become much easier to detect and control. If an answer is wrong, you can trace it back to a source. If a source is missing, you know exactly why the answer is weak. This alone is a massive step forward for enterprise trust.
Third, separation of knowledge from reasoning.
This is the most underrated benefit. Knowledge lives in your systems. Reasoning lives in the model. You can update data without retraining the model and improve reasoning without rewriting your content. That separation is what makes RAG scalable.
Suddenly, AI outputs stop feeling like opinions and start feeling like analysis.

Why Basic RAG Is Still Not Enough
RAG feels like a breakthrough. And compared to raw GPT, it absolutely is. Answers are grounded, sources are visible, and hallucinations are finally put on a leash.
Then teams try to use it for real marketing work, and that’s when the next limitation shows up.
Basic RAG is excellent at answering one question at a time. Marketing, unfortunately, does not work that way. Most marketing questions are not questions at all. They are processes disguised as questions: “Which topics should we prioritize?”, “Why did performance drop?”, “What should we do next?”.
These are not single-shot queries. They require multiple steps, trade-offs, context, and judgment. Basic RAG doesn’t do that. It retrieves, it answers, and then it forgets everything it just did. This is the point where the real question shifts again. Not “How do we get better answers?” but “How do we build systems that can think in steps, remember objectives, and operate within constraints?”
Marketing runs processes. And processes require something more than retrieval and generation.
AI Agents, or a Leap from Answers to Actions
An AI agent is not a smarter prompt and not a chatbot with delusions of autonomy. It’s a system design pattern. At its core, an agent is goal-driven. Instead of answering a single question, it works toward an objective. “Improve content coverage.” “Monitor brand visibility.” “Detect performance anomalies.” The goal persists beyond one interaction.
Agents are tool-using by default. They don’t just talk. They query analytics platforms, pull CRM data, run SEO crawls, check dashboards, and fetch documents.
Agents are memory-aware. They remember what they have already checked, what failed last time, and which constraints apply. This alone eliminates a huge amount of repetitive human oversight.
Most importantly, agents can plan and iterate. They break a goal into steps, execute them, evaluate results, and adjust. If something doesn’t make sense, they can retry with a different approach instead of confidently stopping at the first mediocre answer.
Agents in a Marketing Context
Agents in marketing environments can continuously monitor performance signals across channels, flagging anomalies in traffic, rankings, conversions, or sentiment before a human notices. No dashboards. No daily checks.
Agents can run recurring analyses that humans usually postpone. Weekly SEO coverage reviews, monthly content decay detection, ongoing competitor monitoring. The kind of work that is valuable but rarely prioritized because it’s boring and time-consuming.
Agents also excel at coordinating multiple tools. They can pull data from analytics platforms, enrich it with SEO datasets, cross-check CRM performance, and synthesize insights across systems that normally don’t talk to each other.
This is where AI starts to feel less like a novelty and more like a team member. Not a replacement for marketers, but a force multiplier for analytical capacity.
However, agents are only as good as the information they act on. If they rely on vague or hallucinated knowledge, they simply automate mistakes faster.

Which is why agents alone are not enough either, and that’s where things get truly interesting.
Agentic AI and Agentic RAG
If GPT was “smart text” and RAG was “smart text with sources,” then agentic AI is where things finally start to resemble work.
Agentic AI replaces the prompt mindset with a decision loop.
Instead of: Ask → Answer → Done
You get: Plan → Execute → Validate → Adjust → Repeat
In practice, that means that an agent can say–implicitly, of course–: “I’m not sure yet. I need to check three sources, compare time ranges, and verify the metric definition before I open my mouth.” (which is, frankly, what I wish more dashboards would do).
Agentic RAG
Moving on, combine that decision loop with RAG, and you’ll get the architecture that most enterprise marketing teams actually want, even if they don’t call it this yet.
Agentic RAG means RAG is no longer “the system.” It’s a capability inside the system. Instead of retrieving and generating once, the agent can retrieve multiple times across a multi-step workflow.
Example pattern:
- Pull analytics for the relevant period.
- Retrieve campaign notes and tracking definitions.
- Cross-check with CRM outcomes.
- Retrieve brand guidelines for messaging constraints.
- Generate insight + recommended action.
- Validate that the recommendation is consistent with goals and rules.
AI Workflows: Scaling Beyond One Agent
One agent is impressive, two agents are interesting… but a workflow of agents is where enterprises finally stop experimenting and start building something that can survive longer than a quarter.
Real marketing systems are not powered by a single, all-knowing AI. They are built as orchestrated workflows, where multiple agents handle different parts of the process, much like a real team does. The most effective AI workflows mirror how strong marketing teams actually work.
You have:
- Research agents pulling data from analytics, SEO platforms, CRM systems, and external sources.
- Validation agents checking definitions, time ranges, data freshness, and conflicts.
- Synthesis agents turning structured findings into insights, recommendations, or narratives.
This specialization matters. It prevents premature conclusions, reduces hallucinations, and creates natural checkpoints for quality and compliance.
In other words, you stop asking one agent to be strategist, analyst, auditor, and copywriter at the same time.
Fine-Tuning, LoRA, and When They Actually Make Sense
Every AI discussion eventually reaches the same moment. Someone leans back and says, “Okay, but what if we just fine-tune the model?” This is usually said with the same tone people once used for “What if we just rebuild the website from scratch?” It sounds decisive. And it is very often the wrong first move.
Let’s clear up a few myths.
Fine-Tuning
Fine-tuning means adjusting a model’s internal weights so it behaves differently. Not smarter. Simply differently.
Fine-tuning is useful when you need consistent behavior or style across many outputs. For example:
- Enforcing a specific brand voice
- Standardizing response formats
- Improving performance on narrow, repetitive tasks
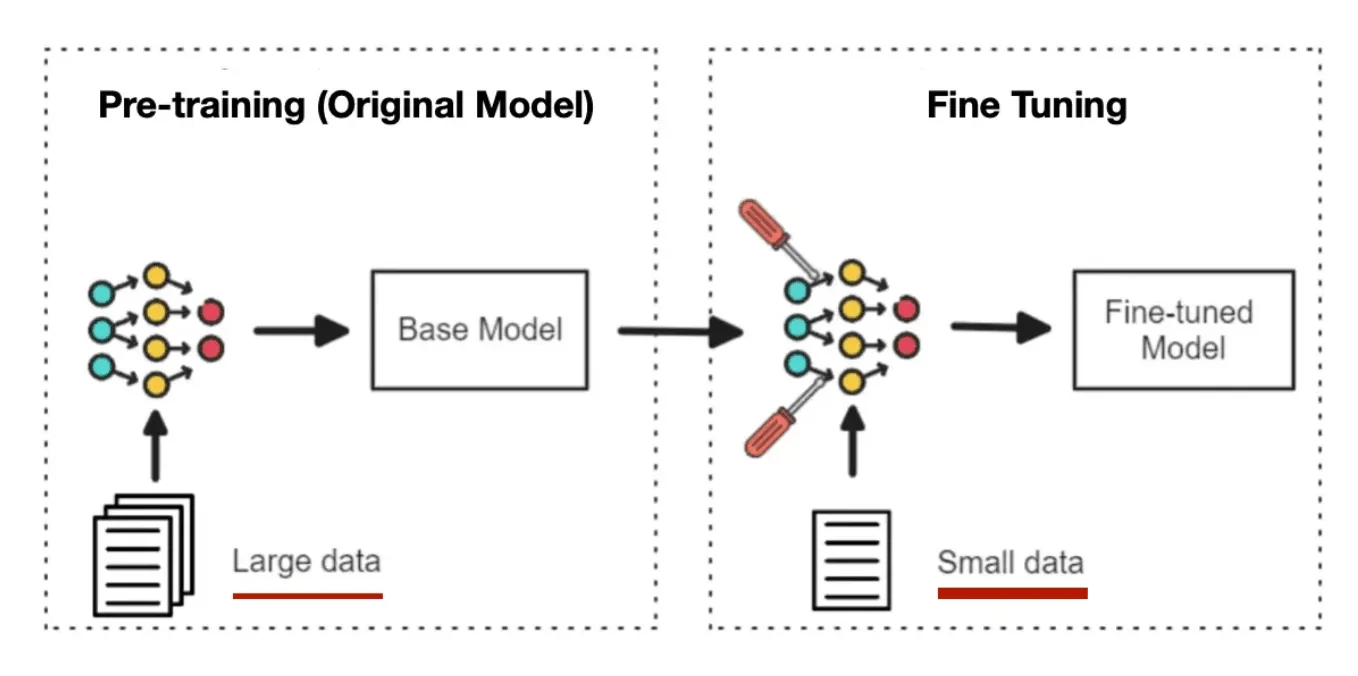
It’s especially effective when the task is stable, and the data does not change frequently. However, fine-tuning is a terrible solution for problems caused by missing or changing data. It does not:
- Make the model more up-to-date
- Teach it your analytics numbers
- Fix hallucinations caused by a lack of foundation
- Replace data access or validation
LoRA (Low-Rank Adaptation)
LoRA exists because enterprises wanted some benefits of fine-tuning without the full operational headache. It allows lightweight adaptation of large models by training a small number of additional parameters instead of touching the entire model. Think of it as adding a lens, not rewiring the brain.
Source: https://pub.towardsai.net/low-rank-adaptation-lora-fedf37b92026
LoRA is appealing because:
- It is cheaper and faster than full fine-tuning
- It can be swapped or rolled back easily
- It allows multiple adaptations on the same base model
- It fits better into controlled deployment pipelines
For enterprises, this means more flexibility and less lock-in.
Meanwhile, LoRA does not replace:
- RAG for grounding answers in live data
- Agentic workflows for multi-step reasoning
- Governance for compliance and risk control
LoRA changes how the model speaks or behaves. It does not change what it knows right now, where that knowledge comes from, or why a decision was made.
Now the final question remains: with all these options, how do you choose the right setup without turning your stack into an AI science project? That’s where comparison and decision frameworks come in.
Choosing AI Architectures That Drive Real Marketing Impact
There is no universally “best” architecture. There are only architectures that are fit for purpose and architectures that look impressive in demos but quietly create operational debt. Instead of arguing opinions, let’s compare them across dimensions that actually matter in enterprise marketing.
Architecture-by-Architecture Reality Check
| Architecture | Data Freshness | Accuracy & Trust | Scalability | Operational Cost | Rsk Control | Time to Insight | Reality Check |
| GPT-only | Very low | Fragile | High for language, low for reality | Low upfront, high downstream | Almost none | Fast (until humans verify) | Great for ideation and drafts. Dangerous for decisions. Human review quietly eats all the time savings. |
| GPT + FIne-Tuning | Low | Slightly improved | Medium | Medium to high | Partial | Fast for narrow tasks | Improves consistency and tone. Does not solve grounding or freshness. Often oversold as a “strategic” upgrade. |
| RAG | High | Strong | Good with solid pipelines | Medium | Moderate | Good | First architecture that feels enterprise-safe. Still mostly single-shot and human-orchestrated. |
| Agent + RAG | High | High | Good | Higher upfront, lower over time | Strong | Verygood | AI starts behaving like an analyst. Introduces goals, memory, and iteration. |
| Agentic RAG + Workflows | High | Very high | Excellent | Higher upfront, lowest at scale | Entreprise-grade | Fastest at scale | Delivers compounding value. Built for reality, not demos. Survives complexity and growth. |
How to Choose the Right Architecture (Decision Framework)
After all the architectures, acronyms, and diagrams, the most dangerous thing an enterprise can do is ask, “Which one should we buy?”
That’s the wrong question. The right question is: Which architecture matches where we are right now, without breaking trust, budgets, or teams?
Team Maturity
Start with people, not models.
If your teams are still experimenting, learning how AI fits into daily work, and mostly using it for support tasks, jumping straight into agentic workflows will feel overwhelming. Architecture should stretch teams slightly, not snap them in half.
Data Complexity
Next question: How messy is your data?
If marketing data is centralized, well-documented, and reasonably clean, simpler architectures can work. If data is fragmented across regions, brands, tools, and definitions, complexity increases fast.
Risk Tolerance
This is where enterprise conversations get very honest, very quickly.
Ask yourself:
- What happens if the AI is wrong?
- Who signs off on outputs?
- Is this internal insight or customer-facing content?
Low risk tolerance environments require:
- Traceability
- Audit logs
- Embedded constraints
High-risk tolerance environments can afford more autonomy, but only if they accept the consequences.
Speed vs Depth
If speed matters most, simpler systems deliver quick wins. If depth matters most, multi-step reasoning becomes unavoidable.
*Hint: Enterprises usually need both, but not for the same tasks.
Experimentation vs Production
Experimentation and production are often blurred, and that’s a line many teams cross only to regret it later.
Experimentation favors fast setup, flexible prompts, and minimal governance, while production demands stability, repeatability, and accountability.
Most AI failures happen when experimental setups are quietly promoted to production without the necessary architectural upgrades. If the system matters, build it like it matters.
The Simple Rule of Thumb
If you remember nothing else, remember this:
- If answers matter → RAG
- If decisions matter → Agents
- If outcomes matter → Agentic RAG + workflows
GPT alone helps you talk about marketing, RAG helps you understand marketing, Agentic systems help you run marketing.
That’s the difference between curiosity and capability.
Wrapping up…
If there’s one idea I hope sticks, it’s this: the future of AI in marketing is not hiding in better prompts.
Marketing leaders who treat AI like magic will keep running pilots.Marketing leaders who treat AI like software will build capability.
AI will keep getting better. Models will keep improving. That part is inevitable. What’s not inevitable is how much value you extract from them. If you design AI like software (not magic), you win.
- If you’re still arguing about prompts, you’re early.
- If you’re designing architectures, you’re already ahead.
- If your AI outputs can be traced, validated, and repeated, you’re building real marketing infrastructure.
And if this article helped you rethink how AI should actually work inside enterprise marketing, then the next step isn’t another tool. It’s better system design.At Digital Loop, we work on complex enterprise MarTech solutions designed for real-world scale. That means moving beyond isolated AI experiments and building systems that are traceable, auditable, and production-ready.
If you’re looking to turn AI from impressive demos into measurable marketing impact, this is exactly the kind of work we focus on. Let’s talk about what this could look like in your setup. Write us here.


